스터디에서 데이콘의 코드를 참고하여 그동안 공부한 내용들을 사용해 실제 데이터에 적용해보는 시간을 가졌었다.
스터디에서 참고한 코드는 아래의 두 편이다. "차트만으로 코스피를 예측할 수 있을까?" 편은 내가 이미 진행한 내용하고 비슷했고, "약형 효율적 시장 가설" 편은 내가 다소 이해하기 어려운 부분들이 있어 생략한 부분들이 많았다. 배운 것을 활용해보고, 다른 사람들의 코드를 참고해봤다는 점에 의의를 두고 싶다.
https://dacon.io/competitions/official/235980/codeshare/6556
차트만으로 코스피를 예측할 수 있을까?
월간 데이콘 KOSPI 기반 분석 시각화 경진대회
dacon.io
https://dacon.io/competitions/official/235980/codeshare/6561
약형 효율적 시장 가설: 기술적 분석에 대한 시사점
월간 데이콘 KOSPI 기반 분석 시각화 경진대회
dacon.io
코드 전문은 깃헙에 있다.
https://github.com/Tiabet/Time-series/blob/master/Time-series/Covid-19.ipynb
GitHub - Tiabet/Time-series
Contribute to Tiabet/Time-series development by creating an account on GitHub.
github.com
그러면 이제 차근차근 내가 진행한 내용을 기록해보겠다.
데이터 수집

국내 사이트에서 확진자 수가 명쾌하게 기록되어 있는 자료를 구하지 못해서, OWID 라는 데이터 수집 사이트를 통해 구할 수 있었다. OWID 에서 제공하는 자료에는 전세계의 코로나 확진자를 아직까지도 매일매일 기록하고 있었다.
https://ourworldindata.org/covid-cases
Coronavirus (COVID-19) Cases
This page has a large number of charts on the pandemic. In the box below you can select any country you are interested in – or several, if you want to compare countries.
ourworldindata.org
이렇게 데이터를 구한 뒤, 원래는 파이썬으로 필요한 데이터프레임만 자를 수 있었지만 코드 짜는 게 귀찮기도 하고 용량이 너무 크기도 해서 그냥 필요한 부분만 복사 + 붙여넣기를 통해 엑셀 파일로 새로 생성했다.
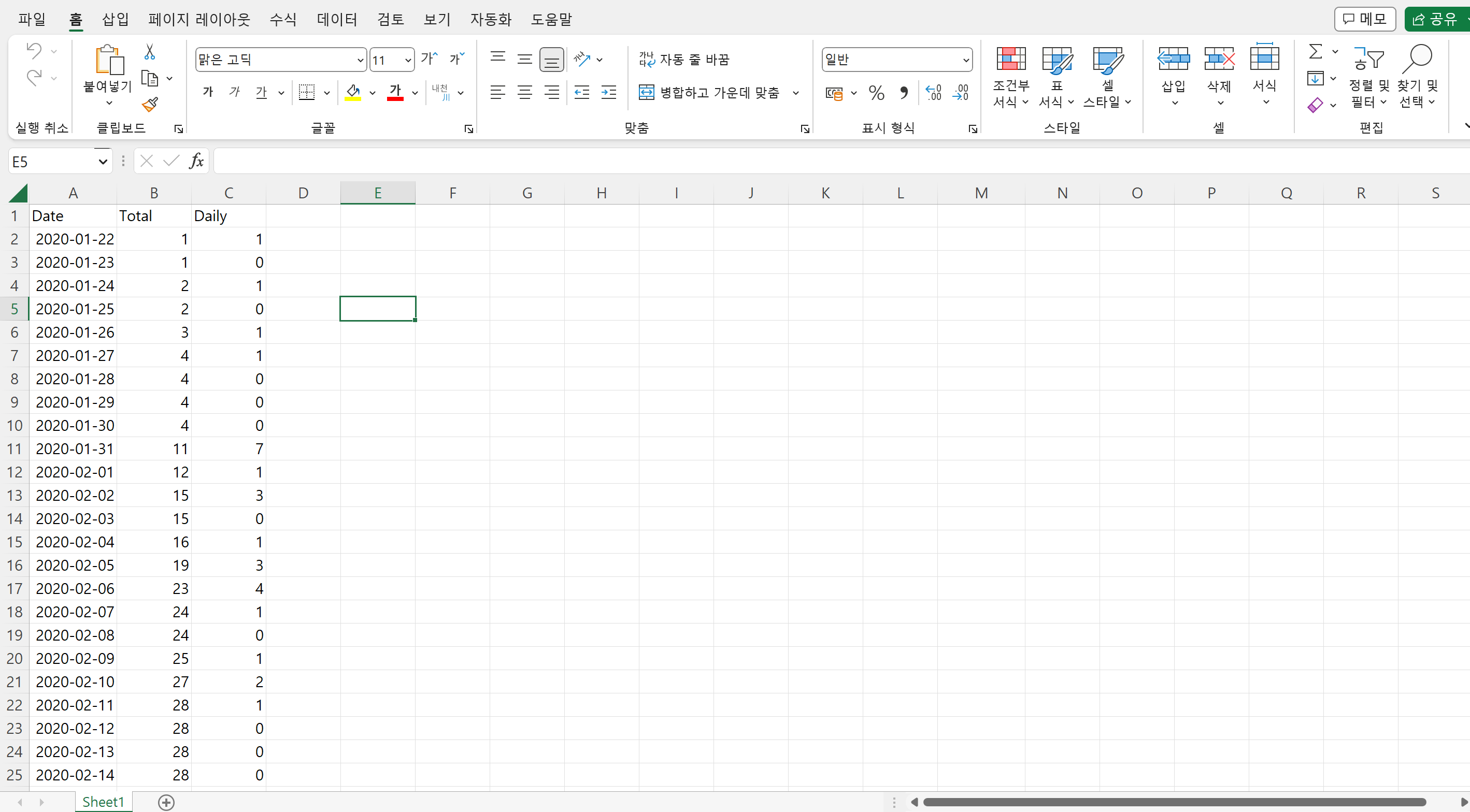
|
1
2
3
4
5
6
7
8
9
|
import pandas as pd
from statsmodels.tsa.ar_model import AutoReg
import matplotlib.pyplot as plt
# Load the data
df = pd.read_excel("Covid19.xlsx")
df
|
cs |
진행 과정
코드는 깃헙에 올라와있는 관계로 다소 생략하겠다.


데이터의 모양이 상당히 좋지 않아서, 코로나 확진자가 유의미하게 증가하기 시작한 1년 전부터의 데이터만 사용하기로 했다.
|
1
2
3
4
5
6
|
today = df.index[-1]
cutoff_date = today - pd.DateOffset(years=1)
df = df[df.index >= cutoff_date]
df
|
cs |

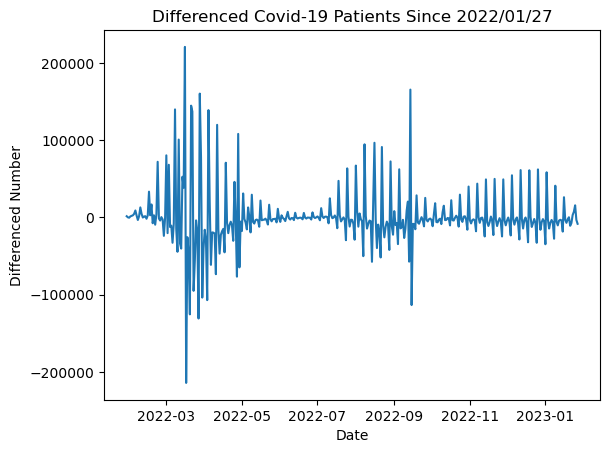
ARIMA 모델을 적용하려면 데이터의 정상성이 중요하기 때문에 ACF, PACF 와 ADF Test 를 통해 데이터의 정상성을 따져보았다.




Test statistic: -2.9906559774390424
p-value: 0.03577627659650839ADF 테스트 결과 p-value 가 0.03으로 차분데이터가 아슬아슬하게 정상성을 갖는 것으로 나왔다. 그런데 ACF 와 PACF 를 보니, 유독 7, 14, 21 등 7의 배수에서 상관계수가 높은 것으로 나왔다. 평소에 코로나 확진자를 유심히 봤던 나는 주말엔 검사자 자체가 적어서 확진자도 적게 나온다는 사실을 알고 있었다. 이것이 상관계수에 영향을 끼친 것이 아닐까 싶어서, 여기서 이 데이터가 계절성을 갖는다고 생각했다. 그래서 SARIMA 모델을 적용하기로 했다.
|
1
2
3
4
5
6
7
8
9
10
|
model = SARIMAX(daily, order=(1, 1, 1), seasonal_order=(0, 1, 1, 7))
model_fit = model.fit()
predictions = model_fit.predict(start=0, end=len(df['diff'])+7)
plt.plot(daily, label='Original data')
plt.plot(predictions, label='SARIMA model')
plt.legend()
plt.show()
|
cs |
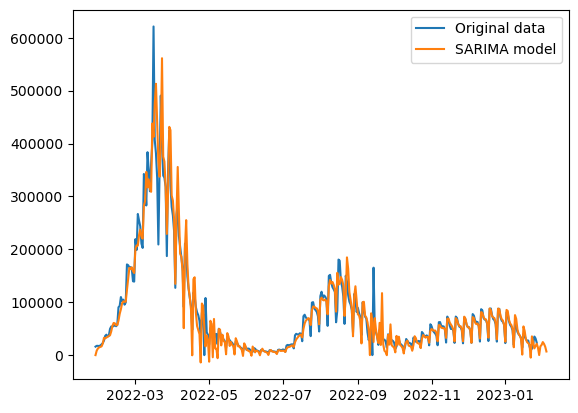

결과가 꽤 나쁘지 않게 나왔따. 아무래도 초창기 급격한 상승량 때문에 잔차가 커진 것을 확인할 수 있다.
여기선 계수를 비계절성 (1, 1, 1), 계절성 (0, 1, 1, 7) 로 설정했다. 사실 이건 임의로 설정한 계수였다. 지금까지 공부한 내용에 따라 ACF 와 APCF를 보고 결정해보자. (비계절성 계수 : pdq, 계절성 계수 : PDQm)
차분 후 데이터의 ACF 와 PACF 에서, ACF와 PACF 모두 시차 0 이후로 급감했으므로 p와 q가 0이 된다. 차분은 1번만 했으므로 d=1이다.
계절성 계수를 보면, ACF와 PACF 모두 급감했지만 시차 7에서 유의미하게 뾰족한 막대가 있으므로 P와 Q가 1이 된다. 계절성 차분의 계수도 자연스럽게 1이 된다.
그래서 배운대로라면 계수를 (0, 1, 0), (1, 1, 1, 7) 로 설정해야 한다. 하지만 밑의 코드를 돌려보고 그렇지 않음을 알게 되었다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
from statsmodels.tsa.statespace.sarimax import SARIMAX
import warnings
import itertools
warnings.filterwarnings("ignore") # to suppress warnings
p = d = q = range(0, 2) # parameter combinations for ARIMA model
pdq = list(itertools.product(p, d, q))
m = [7]
PDQ = list(itertools.product(range(0,2), range(0,2), range(0,2)))
PDQm = [(p,d,q,m[0]) for (p,d,q) in PDQ]
best_AIC = float("inf") # Initialize the best AIC score as infinity
best_params = None # Initialize the best parameters as None
for param in pdq:
for param_seasonal in PDQm:
try:
mod = SARIMAX(daily,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
res = mod.fit()
if res.aic < best_AIC:
best_AIC = res.aic
best_params = (param, param_seasonal)
except:
continue
print("Best ARIMA parameters: ", best_params[0])
print("Best SARIMA parameters: ", best_params[1])
|
cs |
최적의 ARIMA 모델 계수를 찾아주는 코드이다. 비교척도는 AIC를 사용했다. AIC가 작을수록 좋은 모델이므로, 이런 방식을 채택했다. 그랬더니 결과가 (0, 1, 1), (1, 1, 1, 7) 로 나왔다. 그런데 이런 코딩을 해보면서 AIC를 직접 비교해보니, 사실 계수가 1씩 달라진다고 결과가 크게 달라지는 모습은 나오지 않는 것 같다. 이건 다음 포스팅에서 기록해보겠다.
2023-01-27 22712.710555
2023-01-28 14023.872789
2023-01-29 -1616.039497
2023-01-30 18788.058855
2023-01-31 26426.838817
2023-02-01 31954.566041
2023-02-02 26418.787386
2023-02-03 20716.345868
Freq: D, Name: predicted_mean, dtype: float64이게 예측 결과다. 보면 음수값도 나올 정도로 딱히 예측이 좋지는 않았다.

더 먼 미래까지 예측해보라고 해보면 이런 식으로 더 좋지 않은 결과를 보인다. 그래서 아예 계절성을 제거하기 위해 1주일간의 확진자의 총합을 구해서 ARIMA 모델을 돌려보기로 했다. 이는 다음 포스팅에서 다루어보도록 하겠다.
참고로 일일확진자 데이터로 ARIMA 모델을 돌려보면 다음과 같은 결과가 나온다.

2023-01-28 24715.867757
2023-01-29 25007.155828
2023-01-30 25070.059504
2023-01-31 25083.643557
2023-02-01 25086.577034
2023-02-02 25087.210518
2023-02-03 25087.347319
2023-02-04 25087.376862
Freq: D, Name: predicted_mean, dtype: float64그냥 선형으로 추정해버려서 훨씬 더 좋지 않은 결과가 나옴을 확인할 수 있다.
결론
계절성을 띄는 데이터엔 ARIMA 보다는 SARIMA 모델이 훨씬 더 좋은 예측 결과를 얻을 수 있다! 물론 완벽한 예측 결과는 기대하기 힘들다.
다음 포스팅에서 계속
'시계열 데이터' 카테고리의 다른 글
| 시계열 데이터 - 파이썬 auto_arima 및 ARIMA 모델 정리 (2) | 2023.02.13 |
|---|---|
| 시계열 데이터 - 코로나 확진자 수 ARIMA 모델로 예측하기 (2) (0) | 2023.02.10 |
| 시계열 데이터 - 계절성 ARIMA 모델, SARIMA (0) | 2023.02.07 |
| 시계열 데이터 - AR,MA,ARIMA 모델 (2) | 2023.01.21 |
| 시계열 데이터 - 자기상관함수 ACF와 PACF (2) | 2023.01.15 |



