https://tiabet0929.tistory.com/68
[NLP] 트랜스포머 구조 파악하기 (Attention is All You Need)
드디어 오랜 시간 공부해온 트랜스포머에 대해서 정리할 수 있을 정도로 개념이 쌓인 것 같다. 그래서 순차적으로 쭉 자세히 정리해보려고 하는데, 인트로 느낌으로 논문 리뷰를 하면 좋을 것
tiabet0929.tistory.com
이번 포스팅에선 트랜스포머의 임베딩에 대해 자세히 살펴보고자 한다.

트랜스포머엔 가장 처음 Input을 Embedding으로 변환시켜주는 과정이 필수적이다. (다른 Seq2Seq 모델들도 마찬가지)
Embedding(임베딩) 이란 일련의 단어, 즉 문장의 의미와 관계 포착하는 숫자로 변환하는 방법이다.
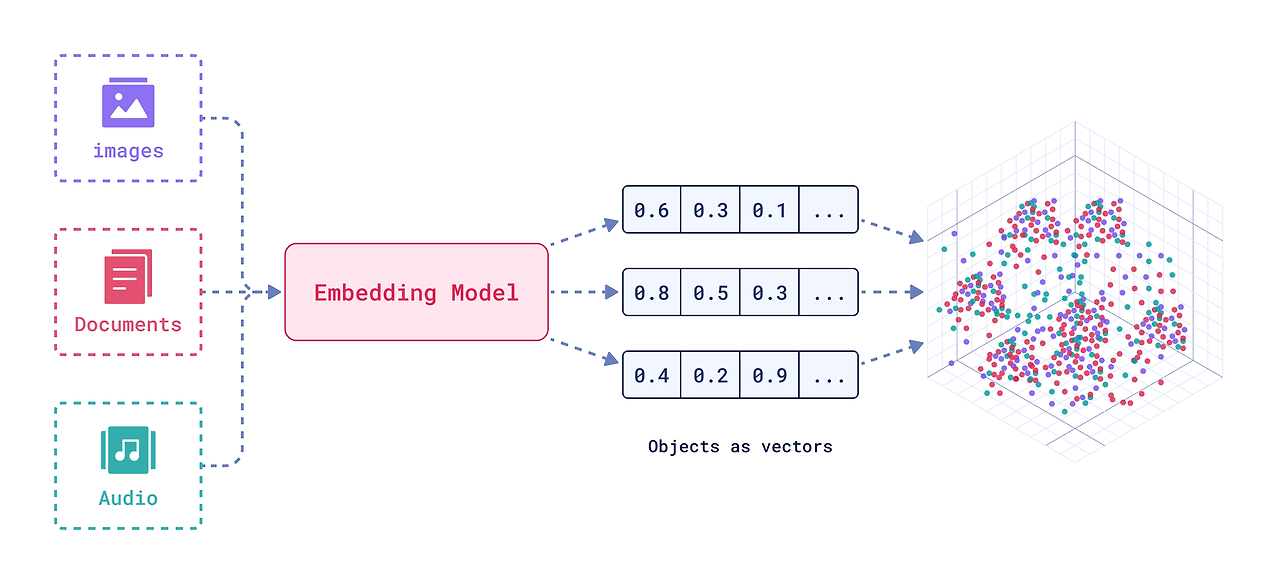
이미지, 문서, 소리 등 많은 비정형 데이터들이 임베딩 모델을 거쳐서 N차원의 벡터로 표현되며, 이 벡터는 그 나름의 의미를 갖고 있다. 예를 들어, 개와 강아지, 애완견 같은 단어들은 N차원의 공간 중 비슷한 위치에 매핑된다. 그러나 코끼리와 책 같은 단어를 보면, 완전히 다른 위치에 매핑되어 있을 것이다. 이처럼 단어들을 매핑하는 과정을 단어 임베딩이라고 부르고, 문장을 매핑하면 문장 임베딩, 그림을 매핑하면 이미지 임베딩이 되는 것이다.
https://www.youtube.com/watch?v=viZrOnJclY0&t=265s&ab_channel=StatQuestwithJoshStarmer
더 자세한 내용은 내가 심심할 때 많이 보는 StatQuest 채널의 영상을 참고.
이번 포스팅에서 집중적으로 살펴볼 것은 실제 모델들에서 임베딩이 어떻게 구현되는가, 그 코드를 보고자 한다.
사실 Attention is All You Need 논문에 소개된 github 에서 Embedding 파트를 찾아보려고 했는데, 찾긴 했는데 너무 어렵게 코딩이 되어있어서 해석하기가 좀 어려웠다. 그래서 Tensorflow와 Pytorch 모두 다른 분들이 코딩해놓은 걸 가져와서 한 번 살펴보려고 한다. 사실 살펴볼 것도 없이, Tensorflow와 Pytorch에서 모두 임베딩 파트는 자체적으로 구현된 Embedding 함수를 사용해서 간단하게 처리해버린다.
# Tensorflow에서의 구현
embedding = tf.keras.layers.Embedding(vocab_size, d_model, mask_zero=True)
if embedding is None else embedding
x = embedding(x)
# Pytorch에서의 구현
#임의의 토크나이저 사용
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "Transformers are amazing!"
tokens = tokenizer.tokenize(text)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
embedding_layer = torch.nn.Embedding(len(tokenizer.vocab), d_model)
input_embeddings = embedding_layer(torch.tensor(input_ids))
확인되는 것처럼 Tensorflow에선 tf.keras.layers.Embedding이라는 모듈을, Pytorch에선 torch.nn.Embedding 모듈을 가져와서 처리하는 것을 알 수 있다. 공통점으론 첫 번째 파라미터로 단어의 크기를, 두 번째로는 모델의 차원을 받는다는 것이다. 추가로 Pytorch에서의 구현 코드를 확인해보면 tokenizer를 사용하여 먼저 input text를 token으로 변환하고, 다시 이 토큰을 숫자들로 변환하는 (convert_tokens_to_ids) 함수가 있는 것을 확인할 수 있다. 이는 Tensorflow에서도 동일하게 적용되는데 적어두질 않았다.
그래서 공식 도큐먼트를 살펴봤다.
https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html
Embedding — PyTorch 2.3 documentation
Shortcuts
pytorch.org
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])Pytorch의 공식 문서의 예제이다. 10개의 단어를 3차원의 벡터로 바꿔주는 embedding을 만들어서 숫자들을 변환시켜보면, 모두 다르게 나오되 [1, 2, 4, 5] 와 [4, 3, 2, 9]에 들어있는 2는 똑같이 [-0.6431, 0.0748, 0.6969] 로 변환되었다.
https://www.tensorflow.org/api_docs/python/tf/keras/layers/Embedding
tf.keras.layers.Embedding | TensorFlow v2.16.1
Turns positive integers (indexes) into dense vectors of fixed size.
www.tensorflow.org
Tensorflow의 예제는 생략하도록 하겠다.
특기할 만한 사실은, 이 Embedding 모듈 또한 파라미터들이 있어서 역전파로 가중치가 업데이트된다는 것이다. 즉, 임베딩을 사용하는 모델들은 문장을 훈련하면서 모델 내 파라미터들만 학습하는 것이 아닌, 문장 자체를 어떻게 임베딩할지 또한 학습하면서 단어와 문장의 의미를 더욱 잘 표현하게 된다.
https://pytorch.org/docs/stable/_modules/torch/nn/modules/sparse.html#Embedding
torch.nn.modules.sparse — PyTorch 2.3 documentation
Shortcuts
pytorch.org
pytorch 내에서의 구현 내용인데 확인해보면 weight 라는 텐서형 변수가 있다.

그리고 이 부분을 확인해보면 Embedding의 forward에서 weight가 업데이트된다고 명시가 되어있다. 따라서 Embedding도 weight, 즉 파라미터가 존재한다는 것을 확인할 수 있다.
정리
1. 트랜스포머에서의 Embedding 레이어는 Pytorch, Tensorflow 모두 내부 모듈 Embedding을 사용하여 간단하게 구현한다.
2. 임베딩 레이어를 거치기 전, Input인 문장을 토큰화하고 숫자로 변환시켜주는 토큰화작업이 필요하다. 이 과정에서 BPETokenizer 등의 토크나이저가 적용된다.
3. Embedding 레이어에도 가중치, 파라미터가 존재한다. 학습과정에서 이 또한 업데이트된다. 이 과정을 통해 비슷한 문장은 비슷한 값으로 임베딩된다.
추가
논문의 언급에 의하면, 인코더의 Embedding Layer와 디코더의 Embedding Layer는 같은 가중치를 공유한다고 한다. 또한 디코더에서 Output을 출력으로 변환할 때도 당연히 같은 가중치가 적용된다. 그리고 가중치를 모델 차원의 루트값을 곱해준다고 하는데 이 부분은 어느 코드를 살펴봐도 구현이 되어있지가 않다. 아마 PyTorch나 Tensorflow의 Embedding 모듈 안에 이미 구현이 되어 있는 듯.
논문에 쓰여있는 모델 차원의 루트값을 곱해서 스케일링 해주는 파트는 인코더 레이어에 구현되어 있었다. 나중에 다룰 예정.
'NLP' 카테고리의 다른 글
| [NLP] Transformer의 Attnetion 간단한 정리 (0) | 2024.06.11 |
|---|---|
| [NLP] 트랜스포머 구조 파악하기 (Attention is All You Need) (2) | 2024.06.11 |
| [NLP] Transformer의 Positional Encoding 정리 (0) | 2024.06.06 |
| [NLP] 트랜스포머 사용 시 숫자 텍스트 데이터 전처리에 대해 (0) | 2024.04.18 |
| [NLP Study] - LSTM (2) | 2024.03.22 |


