[딥러닝] 역전파를 단 한 줄로 가능하게 해주는 backward() 함수 탐구
많은 사람들이 딥러닝 이론을 공부할 때 가장 열심히 공부하는 부분이 역전파 부분일 것이다.
그 이유는 단순한데, 역전파가 있어야 딥러닝이고 또 그 과정이 만만치 않게 복잡하기 때문이다.
https://www.youtube.com/watch?v=tIeHLnjs5U8&ab_channel=3Blue1Brown
내가 공부하면서 본 유튜브 채널 중 하나인데, 간단한 예제로 역전파 계산 방법에 대해서만 10분짜리 영상이 나올 정도로 그 계산이 쉽지 않다. 미분이 떡칠되어 있기 때문이다. 그래서 이 부분으로 필기시험을 본다면 아마 그 시험에서 가장 계산량이 많은 파트일 것이다.
그런데 코딩을 하게 되면 말이 다르다. 가장 어려운 부분인 기울기 계산은 pytorch 기준으로는 backward() 함수 한 줄이면 끝나고, tensorflow 기준으로는 tf.GradientTape().gradient() 만 쓰면 끝나서 이 과정이 굉장히 단순하다.
따라서 이번 포스팅에선 어떻게 이 함수 한 줄로 사람이 손으로 하면 절대 불가능한 긴 연산이 가능한 것인지 그 구조를 탐구해보고자 한다. 내가 요즘 많이 쓰는 게 pytorch라서 pytorch 기준으로 공부했다.
backward() 함수의 유용성
내가 backward 함수를 사용하면서 정말 유용하고 좋다는 느낌을 받은 것은 관련된 텐서를 별다른 입력 없이 모두 추적할 수 있기 때문이었다.
import torch
# 입력 데이터
x = torch.tensor(2.0, requires_grad=True) # 학습 가능한 변수
y = torch.tensor(3.0, requires_grad=True)
# Forward pass: 계산 그래프 생성
z = x * y # 곱셈 연산
loss = z ** 2 # 손실 함수 (제곱)
# Backward pass: 기울기 계산
loss.backward()
# 출력
print("z:", z.item()) # z 값
print("Loss:", loss.item()) # 손실 값
print("Gradient of x:", x.grad.item()) # x에 대한 기울기
print("Gradient of y:", y.grad.item()) # y에 대한 기울기GPT가 생성해준 backward() 함수의 예시를 보면, loss 함수로는 z^2 (z = x*y) 라는 아주 간단한 식을 사용하고 있고, 입력 텐서인 x 와 y 또한 정수 하나로 아주아주 간단한 예시이다. 하지만 실제로 기울기를 계산할 때에는 loss.backward() 한 줄로 다 해결이 된다. 그러면 loss에 연결된 모든 텐서들(단, 기울기를 추적한다는 명시를 해줘야 한다. requires_grad = True 를 통해 기울기를 추적하겠다고 선언했다.)의 기울기를 컴퓨터가 다 계산을 해준다.
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 데이터 정의 (y = 2x + 1)
x_data = torch.tensor([[1.0], [2.0], [3.0], [4.0]]) # 입력 데이터
y_data = torch.tensor([[3.0], [5.0], [7.0], [9.0]]) # 출력 데이터
# 2. 모델 정의
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1) # 1 input feature, 1 output feature
def forward(self, x):
return self.linear(x)
model = LinearRegressionModel()
# 3. 손실 함수와 옵티마이저 정의
criterion = nn.MSELoss() # Mean Squared Error
optimizer = optim.SGD(model.parameters(), lr=0.01) # Stochastic Gradient Descent
# 4. 학습 루프
num_epochs = 100
for epoch in range(num_epochs):
# Forward Pass: 예측값 계산
predictions = model(x_data)
loss = criterion(predictions, y_data)
# Backward Pass: 기울기 계산
optimizer.zero_grad() # 기존 기울기 초기화
loss.backward() # 손실에 대한 기울기 계산
# 가중치 업데이트
optimizer.step() # 가중치 업데이트
# 10번마다 학습 상태 출력
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
# 5. 학습된 파라미터 출력
print("Learned weight (w):", model.linear.weight.item())
print("Learned bias (b):", model.linear.bias.item())
이후 이런 식으로 optimizer와 조합하면, 딥러닝 모델을 훈련시킬 수 있는 세팅이 완료되는 것이다.
그럼 내가 진짜 궁금했던, 어떻게 이 한 줄로 loss에 연결된 모든 텐서의 기울기가 다 추적되는지를 확인해보고자 한다.
정답은 torch의 backward() 함수에는 내부적으로 그래프를 만들어 저장한다고 한다.
https://pytorch.org/docs/stable/_modules/torch/autograd.html#backward
torch.autograd — PyTorch 2.5 documentation
Shortcuts
pytorch.org
여기 소스코드가 있긴 한데, 사실 내부 패키지 코드는 뜯어봐도 이해가 안 가는 것이 사실이다. 그래서 이 그래프라는 것만 알아보기 위해서 파라미터를 따라가봤다.

backward 함수는 보통 파라미터 없이 쓰는 것이 대부분이지만 이렇게 retain_graph, create_graph 라는 파라미터가 존재하는 것을 확인할 수 있다.

그리고 이 설명을 읽어보면, retain_graph가 False일 경우에는 그래디언트를 계산하는 데에 사용된 그래프가 해방된다(freed)고 표현하는데, 영어권에서 smoking free가 금연을 의미하는 것처럼 free는 보통 없다, 안 된다는 느낌으로 사용되는 것을 보면 그래프가 없어진다고 생각하면 된다. 그리고 대부분의 경우에서 이 파라미터를 True로 설정할 필요가 없다고 하며, create_graph를 True로 놓으면 고순위대로 미분을 처리할 수 있는 그래프를 생성할 수 있게 된다고 한다.
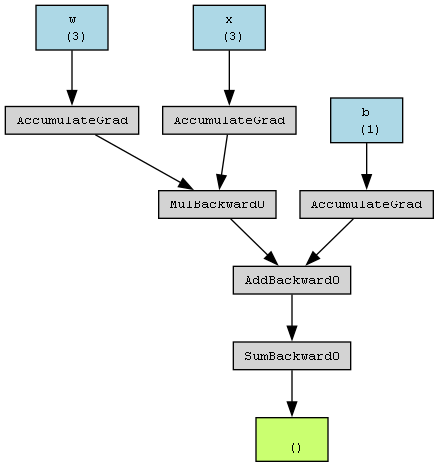
즉, 뭔지는 확인은 불가능하지만 pytorch의 텐서 내부에는 이런 연산을 처리할 수 있는 그래프가, 최소한 이런 그래프의 기능을 하는 무언가가 실제로 존재한다는 것이다. 간절하게 이 부분을 확인하고 싶은데 여기저기 뒤져봐도 도저히 찾을 수가 없고, 마찬가지로 gpt에게 물어봐도 원하는 답변은 얻을 수 없었다.
결론 : pytorch의 내부에는 tensor끼리 연산을 하면 이 tensor들끼리 다 연결이 되는데, 이를 backward 함수가 추적하여 기울기를 잘 업데이트해주어 역전파가 가능하다.